

Por Ignacio Fibla, Data Scientist en Notus
Las hospitalizaciones en los departamentos de urgencia son procesos complejos y se caracterizan por tener tiempos de espera elevados. Esto no solo depende del recinto de salud al cual acudimos, si no también, de la temporada en que visitamos este departamento en específico. Por ejemplo, es más probable que en invierno nos encontremos con un sector de urgencias totalmente repleto y que en verano las patologías respiratorias disminuyan, y por ende, que este sector esté un poco más expedito.
De hecho, el diario La Tercera destaca que “según datos del Ministerio de Salud, en 2022 fueron 468.056 los pacientes que llegaron a las urgencias del país y recibieron indicación de hospitalizarse. De ese grupo, el 63% fue ubicado en una cama antes de 12 horas, mientras que el 37% restante superó ese plazo”. Estas cifras son preocupantes debido a las fatales consecuencias que pueden ocurrir si es que un paciente no llega a poder ser hospitalizado de forma oportuna.
En Notus hemos desarrollado distintas herramientas de Machine Learning para la predicción de hospitalización de los pacientes, enfocadas en aquellos que acuden a urgencias. El objetivo de este breve artículo será revisar y comparar distintos modelos de clasificación que nos permitan predecir si un paciente que acude a urgencias deberá ser hospitalizado o no. De esta forma se puede agilizar el proceso de ubicar a las personas que deben hospitalizarse en una cama y, de este modo, disminuir los tiempos de espera de las salas de urgencia.
Metodología
Con este objetivo en mente, utilizaremos un dataset de pacientes con su edad, sexo y datos provenientes del proceso de triage. Con este nombre se conoce al proceso previo a la consulta de diagnóstico, en el cual se prioriza el orden de atención a los pacientes según la gravedad o urgencia del paciente. De este proceso se extraen los datos de su duración, motivo de consulta y los pre-diagnósticos del paciente realizados por la parte de enfermería.
Para tratar estos datos, en primer lugar, hicimos una limpieza de la columna de texto que representa el motivo de la consulta. Donde utilizamos la librería spaCy, la cual nos permite lematizar el texto presente. Lematizar es un proceso lingüístico en donde se transforma el texto a su forma base. Por ejemplo, la palabra “sangrado” se transforma a “sangrar”. Esto con el objetivo de tener un manejo más eficiente en términos de tiempo y memoria.
Como metodología general se utilizarán modelos de clasificación de 2 etiquetas. De esta forma las opciones toman valores de 1, si es que se predice que el paciente debe ser hospitalizado, o 0 si el paciente no debe ser hospitalizado.
Uno de los grandes desafíos de este análisis es que la clasificación de texto. En este caso, la clasificación de motivo de visita, es más compleja que la clasificación de otras variables numéricas. Es por esto que se utilizaron 6 métodos diferentes para resolver este problema. Las metodologías fueron las siguientes:
● Método 1: Usaremos Bag of Words (BOW), el cual consiste en transformar las palabras a vectores de números representados con 1 y 0. Por ejemplo, si la palabra dolor se encuentra en nuestra columna de texto, entonces se crea la columna con encabezado “dolor”. Donde todos los pacientes que tengan esta palabra dentro de este motivo de consulta entonces tendrán un valor 1 en esta columna y 0 en el caso contrario. De esta forma, ocupamos el modelo regresión logística, un modelo típicamente utilizado para problemas de clasificación, para predecir si el paciente será hospitalizado o no.
● Método 2: Otro método es BERT (Bidirectional Encoder Representations from Transformers), el cual es un modelo de redes neuronales desarrollado por Google. Esto nos va a permitir vectorizar las palabras con las que contamos en nuestra columna de texto. Así mismo, ocupamos el modelo de regresión logística para predecir si el paciente será hospitalizado o no.
● Método 3: Word2Vec es otra metodología la cual consta de una red neuronal. Esta nos permite pasar de palabras a números tomando en cuenta la similitud entre las palabras y sus contextos. De la misma manera ocupamos el modelo regresión logística para predecir si el paciente será hospitalizado o no.
● Método 4: TF-IDF (Term frequency – Inverse document frequency), modelo similar a BOW, pero en donde se tienen en cuenta las frecuencias de aparición de cada palabra en la columna de texto (por ende, no solamente se toman valores 0 o 1). De igual manera ocupamos el modelo regresión logística para la predicción.
● Método 5: Para este método utilizamos CatBoostClassifier. Este es un modelo de clasificación que sí acepta entradas de texto. Se utilizará directamente para predecir si el paciente será hospitalizado o no.
● Método 6: Para el último método utilizamos un modelo externo. El cual utiliza distintas librerías de Python, pero especialmente se utiliza la librería sentence transformers de Hugging Face para el tratamiento de texto, y posterior a esto, utiliza un modelo de clasificación conformado por redes neuronales, el cual proviene de la librería pytorch.
Si nos damos cuenta, la regresión logística es utilizada en los métodos 1, 2, 3 y 4, pero … ¿En qué consiste este método? ¿Por qué lo utilizamos? La regresión logística es un método de clasificación ampliamente utilizado en problemas de clasificación binaria, donde solo se contemplan dos resultados posibles (por ejemplo, «verdadero/falso», «1/0» o «sucede/no sucede»). En este contexto, se utiliza para predecir si un paciente «debe ser hospitalizado» o «no debe ser hospitalizado». El modelo considera una variedad de características de entrada, como la edad, altura, peso y otros factores relevantes. A partir de estas características, se ajusta una curva logística en forma de «S» que actúa como una frontera para separar las clases «hospitalizado» y «no hospitalizado».
El uso de este método de clasificación sobre los otros, es por la eficiencia y rapidez, ya que los métodos presentados generan una gran cantidad de variables de entrada para el modelo, por lo que se hace necesario un método que maneje con rapidez y precisión los conjuntos de datos de gran tamaño, como también, va en la relación con que queremos un método que pueda predecir rápidamente la hospitalización de un paciente, para así reducir el tiempo de espera de hospitalización de este. Por último, la simpleza de este método hace que su interpretabilidad sea bastante alta, ya que dentro del análisis de resultados este método nos entrega herramientas que nos permiten entender directamente cómo las variables de entrada afectan la probabilidad de pertenencia a una clase.
En la Imagen 1, mostramos un ejemplo ficticio de cómo funciona la regresión logística en nuestro problema, usando solo la edad del paciente como variable. A medida que la edad del paciente aumenta, la probabilidad de requerir atención hospitalaria también aumenta, especialmente debido a los cuidados extras que deben tener las personas de avanzada edad. Los pacientes por encima de la curva son clasificados como aquellos que deben ser hospitalizados, mientras que los que están por debajo se consideran no hospitalizados según el modelo.
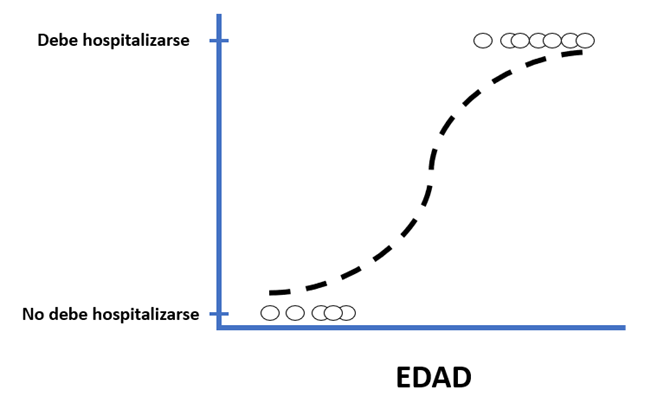
Imagen 1: Ejemplo de regresión logística de Machine Learning
Resultados
Para evaluar estos métodos de clasificación utilizaremos 3 métricas diferentes relevantes a la hora de comparar resultados. Estas métricas corresponden al tiempo y la exactitud (representado generalmente como accuracy). Esta corresponde a un indicador que toma un valor entre 0 y 1 y es la razón entre predicciones correctas y predicciones totales. La última métrica que utilizamos es la matriz de confusión, la cual nos permite observar de manera gráfica e ilustrativa los siguientes elementos:
● Verdaderos positivos: Representa el número de predicciones de hospitalizados que sí tenían que ser hospitalizados.
● Verdaderos negativos: Es la cantidad de predicciones de no hospitalizados que no tenían que ser hospitalizados.
● Falsos positivos: Indica el número de predicciones de hospitalizados que no tenían que ser hospitalizados.
● Falsos negativos: Se refiere a la cifra de predicciones de no hospitalizados que si tenían que ser hospitalizados.
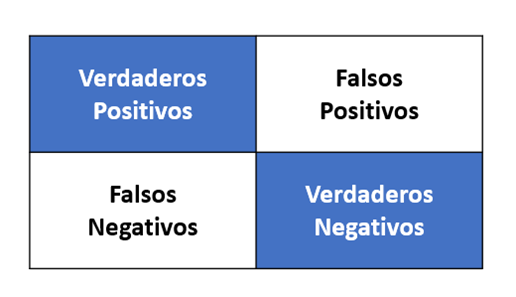
Imagen 2: Ilustración de Matriz de confusión en Machine Learning
Por otro lado, la tabla 1 resume los resultados en término de tiempo de ejecución del modelo (entrenamiento y predicción) y su indicador de accuracy.
| Método | Tiempo de ejecución del modelo | Accuracy |
| Método 1 | 30 Segundos | 0.845 |
| Método 2 | 13 Segundos | 0.843 |
| Método 3 | 4 Segundos | 0.843 |
| Método 4 | 8 Segundos | 0.84 |
| Método 5 | 118 Segundos | 0.85 |
| Método 6 | 1860 Segundos | 0.9 |
Tabla 1: Tabla resumen accuracy por modelo de Machine Learning y tiempos de ejecución
Por último, es posible visualizar las matrices de confusión para los modelos.
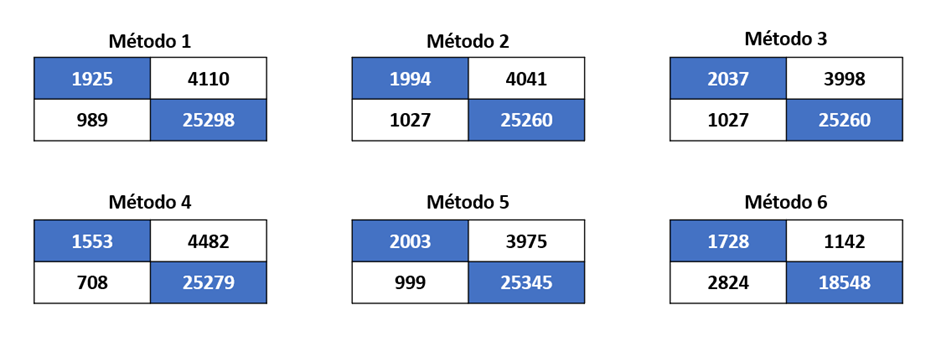
Imagen 3: Resúmenes Matrices de confusión para cada modelo de Machine Learning
Si bien, las métricas de exactitud y las matrices de confusión son parecidas entre los métodos, el método 5 resulta ser el mejor ya que se ajusta a los requerimientos del problema. Esto ocurre debido a que su accuracy es levemente mejor que los métodos 1, 2, 3 y 4. Si bien, el método 6 presenta un mejor accuracy general, nos debemos centrar en qué tan bueno es el método para predecir pacientes que sí deben ser hospitalizados. Para esto, podemos usar la precisión del modelo para pacientes necesitan hospitalización, la cual podemos destacar como:
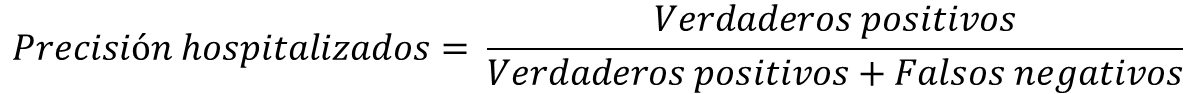
Es acá donde el método 5 tiene 66% de precisión de hospitalizados y el método 6 obtiene solo un 39%. Esto que nos indica que el método 6 únicamente tiene un mejor accuracy que los otros métodos porque es bueno prediciendo los pacientes que no serán hospitalizados. Por último, el método 5 tiene la ventaja de brindar mejores predicciones de forma bastante rápida (en menos de 1 segundo). Esto ocurre debido a que se puede guardar el entrenamiento de este y no tiene la necesidad de ser entrenado cada vez que ingrese un nuevo paciente a urgencias.
La rapidez y precisión del modelo responden a lo que mencionamos en la introducción sobre las consecuencias graves de no hospitalizar a un paciente que necesita hospitalización de forma urgente. Especialmente este modelo contrarresta los grandes tiempos de espera por los que generalmente pasan estos pacientes, posee una gran precisión y tiene la gran ventaja de poder seguir siendo entrenado para ser aún más preciso a medida de que ingresen nuevos pacientes a urgencias.
Discusiones futuras
Las herramientas de Machine Learning nos otorgan una gran oportunidad de análisis. En esta oportunidad revisamos el desempeño de distintos modelos de clasificación y lo efectivo que pueden ser para predecir la hospitalización de personas que acuden a urgencias. También descubrimos que es posible ampliar los análisis a otros procesos de toma de decisiones. En este caso, podemos observar que los modelos presentados pueden ejecutarse una vez se realice el procedimiento de triage en la zona de enfermería, una vez obtenido los resultados, si el modelo predice que el paciente debe ser hospitalizado, entonces se pueden tomar las medidas necesarias para atender al paciente de forma inmediata o prioritaria (para verificar si debe ser hospitalizado). De esta forma, se reduce el tiempo de espera para un paciente que necesita ser hospitalizado con mucha urgencia.
Se debe considerar además que el conjunto de datos de ejemplo utilizado en este análisis cuenta con poca información. Para un análisis más profundo es posible incorporar datos como signos vitales (temperatura, presión, saturación), el historial médico del paciente y resultados de exámenes de cada paciente.
Esta es solo una pequeña aplicación de lo que se puede a llegar a implementar con Machine Learning, específicamente en el área de la salud podemos tratar distintos tópicos. Tales como la predicción de no shows (si un paciente se presentará a su cita agendada con el médico), el largo de estadía de un paciente, entre otros, combinando la ciencia de datos y la optimización. En Notus tenemos amplia experiencia en las diversas áreas y aplicaciones del Machine Learning, adaptando cada problema a tus necesidades y dolencias. ¿Tienes alguna decisión compleja que tomar en la que te podamos ayudar a predecir sus resultados? ¡Conversemos!

