

En un mundo donde la carrera por la creación del modelo de inteligencia artificial más grande y poderoso parece no tener límites, es crucial detenerse un momento para reflexionar en los requerimientos de las funcionalidades que necesitamos en nuestros proyectos. Los modelos actuales de inteligencia artificial ya han alcanzado un nivel de excelencia que los hace perfectamente adecuados para una multitud de aplicaciones, por lo que aspectos como costos, viabilidad de la implementación y la privacidad de los datos comienzan a ocupar un lugar destacado en la conversación.
A continuación, desglosamos una nueva tendencia en los modelos de lenguaje, que abordan precisamente estos temas. Se trata de los modelos Mistral. Con un tamaño compacto y licencia Apache 2.0, este modelo ofrece un rendimiento destacado sin las restricciones asociadas a modelos de grandes empresas.
¿Qué es Mistral AI?
La startup de inteligencia artificial Mistral AI, con sede en París y cofundada por exalumnos de DeepMind y Meta de Google, ha logrado un hito significativo en el panorama europeo. Recientemente, cerraron una ronda de financiación de 385 millones de euros, lanzándose en tiempo récord hacia el estatus de unicornio en Europa. Aunque la valoración exacta tras esta operación no ha sido revelada, se estima rondaría los 2.000 millones de euros, según fuentes de Bloomberg. La exitosa transacción fue liderada por Andreessen Horowitz y Lightspeed Venture Partners, este último ya con participación en la startup.
En el ámbito de la constante evolución del Procesamiento del Lenguaje Natural (NLP), la carrera hacia un rendimiento de modelo más alto a menudo requiere una escalada en el tamaño del modelo. Sin embargo, este aumento en la escala tiende a incrementar los costos computacionales, lo que eleva las barreras para su despliegue en escenarios prácticos del mundo real. Adicionalmente, muchas de las aplicaciones actuales funcionan eficazmente con los modelos existentes, lo que sugiere que no siempre se necesitan sistemas más potentes, sino más bien soluciones que ofrezcan precios competitivos y flexibilidad para implementar estas aplicaciones en situaciones reales. En este contexto, la búsqueda de modelos equilibrados que ofrecen tanto un rendimiento de alto nivel como eficiencia se vuelve críticamente esencial.
¿Qué es lo que diferencia de otros tipos de modelos?
En Deep Learning, los modelos suelen reutilizar los mismos parámetros para todas las entradas, lo cual no es un problema per se, pero mientras los modelos se van complejizando van aumentando su tamaño, este valor puede volverse más de 70 mil millones en los más potentes. Lo cual no es un problema para las grandes compañías y sus servidores de gran potencia, pero para el resto de los mortales se ve cada vez más difícil de lograr.
He aquí la respuesta del más reciente modelo de Mistral AI, Mixtral 8X7B, el cual se destaca por su arquitectura basada en sparse Mixture of Experts (SMoE). En lugar de utilizar todos los parámetros se seleccionan un conjunto de parámetros de acuerdo al requerimiento inicial. Para ilustrarlo mejor, imagina que tienes una pregunta de matemáticas, este modelo usaría su red de acceso para dirigir la pregunta a los expertos adecuados, en este caso sería a los que manejan tareas matemáticas. Cada experto realizaría su propio procesamiento y aprendizaje, y finalmente, el modelo generaría una respuesta basada en su procesamiento.
El resultado es un modelo activado de manera dispersa, con una cantidad increíble de parámetros, pero un costo computacional constante. Específicamente, Mixtral 8x7B está compuesto por 8 expertos, cada uno con 7 mil millones de parámetros. Sin embargo, el modelo global no es de 56B sino de 47B, dado que se cruzan los parámetros entre expertos.
A continuación se muestra el rendimiento del modelo Mixtral 8x7B:
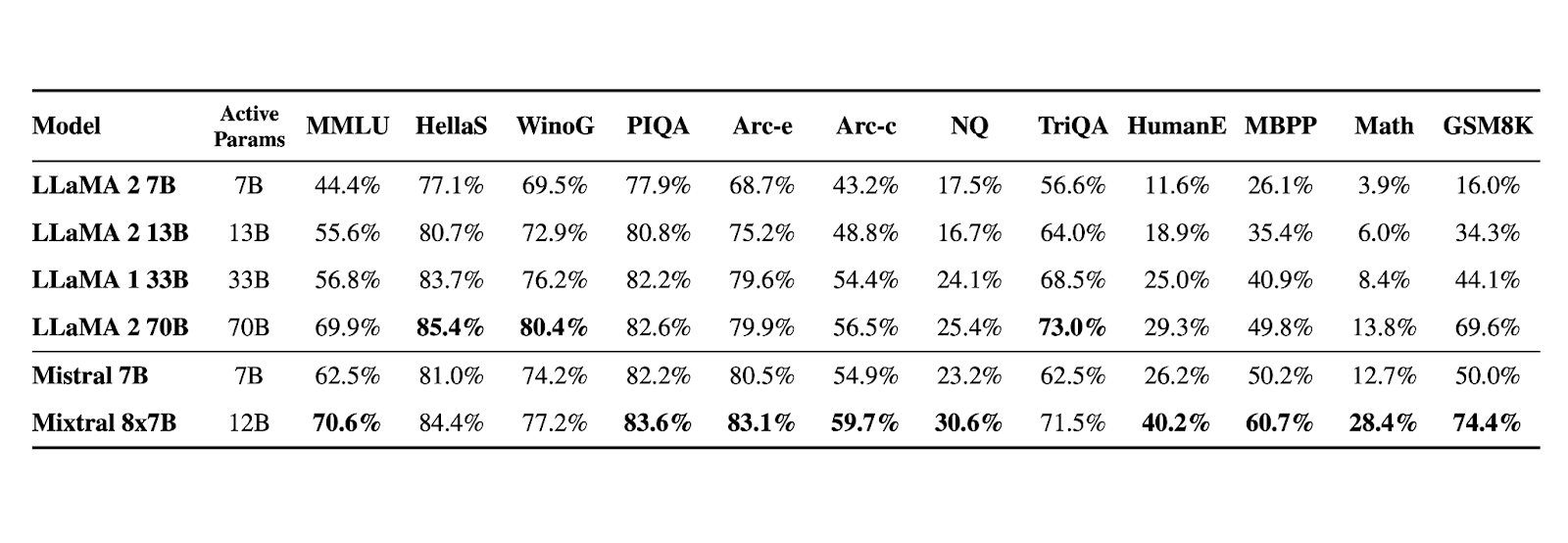
¿Cuál fue nuestra experiencia en Notus?
En Notus nos enfrentamos a un desafío emocionante al colaborar con la empresa CompuMat, una plataforma online orientada especialmente a la educación a distancia, que buscaba incorporar inteligencia artificial en su sistema de enseñanza de matemáticas. La premisa era clara: utilizar la IA para mejorar y complementar la experiencia educativa existente. Nuestro equipo optó por un enfoque inicial que involucra la aplicación de un tutor de matemáticas virtual respaldado por los modelos grandes de lenguaje (LLM).
En el proceso de desarrollo y pruebas, decidimos probar el potencial de GPT-4, el modelo más potente a la fecha de OpenAI, para diversas funcionalidades. Los resultados fueron positivos, el cliente se mostró sorprendido y motivado a seguir profundizando en el proyecto. Sin embargo, el mayor desafío surgió al intentar determinar los costos asociados con las diferentes alternativas para implementar el modelo en una base de datos considerable, que constaba de más de 40 mil problemas matemáticos.
¿Cómo estimamos los costos y elegimos un modelo adecuado?
Para la estimación de costos del modelo GPT-4, se aplican tarifas diferenciadas para la entrada y la salida del modelo. En concreto, se establece un costo de 0,03 dólares por cada 1,000 tokens procesados en la fase de entrada, mientras que la fase de salida tiene una tarifa de 0,06 dólares por cada 1,000 tokens generados. La forma actual de funcionamiento nos entrega un coste promedio de la primera respuesta de: 0.08 USD. Por ejemplo: Para una sesión de un curso de 40 alumnos donde supongamos que cada niño interactúa 5 veces con el tutor, el costo aproximado sería de entre 8 a 12 USD.
| Token System Message + Descripción | Token Respuesta 1 | Token Prompt | Token System Message + Descripción + Respuesta 1 + Prompt | Token Respuesta 2 | Cost Input | Cost Output | Total Cost Interacción |
| 1069 | 129 | 48 | 1246 | 159 | $0.07 | $0.02 | $0.09 |
Una de las opciones que consideramos fue el uso de modelos de inteligencia artificial de código abierto, que ofrecían un rendimiento comparable a GPT-4 sin incurrir en costos de uso de la API. Sin embargo, estos modelos demandaban una gran capacidad de procesamiento, lo que nos llevó a explorar soluciones como Runpod para alquilar PCs con potentes tarjetas gráficas. Esto, naturalmente, se traducía en costos adicionales considerables. Sobre todo cuando se consideraba que la aplicación debía ser usada de manera paralela con múltiples usuarios simultáneamente, se requería una infraestructura robusta de servidores, lo que plantea desafíos adicionales para integrar estos modelos con las aplicaciones educativas existentes del cliente.
Luego con estos datos decidimos…
En este punto, se produjo un trade-off significativo entre el rendimiento y los costos asociados. Aquí es donde los modelos Mistral nos ofrecieron una oportunidad única. Su ligereza les permitió ejecutarse eficientemente en la computadora local del cliente, reduciendo así la necesidad de infraestructura costosa y potenciando su capacidad para integrarse perfectamente con las aplicaciones educativas preexistentes.
Esta decisión estratégica de optar por modelos más livianos como Mistral no sólo ayudó a mitigar los costos operativos, sino que también abrió una ventana de oportunidad para el cliente. Les proporcionó una solución efectiva y rentable para aprovechar la inteligencia artificial en su sistema educativo, manteniendo la calidad y la eficacia sin comprometer su presupuesto.
La experiencia de trabajar con Compumat para implementar modelos Mistral destacó la importancia de encontrar soluciones adaptables y eficientes en el ámbito de la inteligencia artificial, demostrando que la elección correcta de tecnología puede marcar una diferencia significativa en términos de viabilidad y éxito del proyecto. ¿Tienes algún proyecto donde sería beneficioso utilizar un modelo más compacto? Conversemos.
Referencias
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. D. L., … & Sayed, W. E. (2023). Mistral 7B. arXiv preprint arXiv:2310.06825.
[2310.06825] Mistral 7B (arxiv.org) link de lo anterior
Wang, R., Chen, H., Zhou, R., Duan, Y., Cai, K., Ma, H., … & Tan, T. (2023). Aurora: Activating Chinese chat capability for Mistral-8x7B sparse Mixture-of-Experts through Instruction-Tuning. arXiv preprint arXiv:2312.14557.

