

Por Pablo Senosiain, socio de Notus
Introducción
Pensemos por un momento que tenemos un amigo que es fanático de Albert Einstein y de todo su trabajo científico. Llamemos a nuestro amigo: Gaspar Perez Torres (a.k.a. GPT). Nuestro amigo tiene además una excelente memoria, por lo que es capaz de memorizar cualquier artículo científico. Cada vez que puede, nuestro amigo se pone a recitar alguno de los papers que Einstein publicó en su annus mirabilis o “año milagroso”, periodo en el cual el científico publicó sus aportes más grandes a la ciencia.
Imaginemos una situación: En una reunión de amigos, entre risas y cervezas, Gaspar comienza a recitar una vez más una de las obras maestras de Einstein, pero como ya lo conocemos hace tiempo, no le damos mayor importancia. Sin embargo, desde la mesa del lado, dos personas que no lo conocen lo escuchan atentamente por más de 10 minutos y quedan asombrados. No pueden creer el dominio que tiene Gaspar en temas de relatividad especial. ¿Están escuchando al próximo Albert Einstein de nuestra época? Ante su asombro nos preguntamos ¿Hasta qué punto podemos considerar inteligente a Gaspar?
Este caso hipotético nos puede ayudar a entender y reflexionar sobre algunas de las discusiones que se están dando hoy en el mundo respecto a la Inteligencia Artificial: ¿Cuáles son las reales capacidades de los modelo de lenguaje como GPT4 o Gemini? ¿Estamos ante una tecnología que compite (o competirá) con la inteligencia humana? ¿Hasta dónde podrían los LLM reemplazar el trabajo de los humanos?
Una aparente inteligencia
Volviendo con Gaspar, es esperable y entendible que personas que lo escuchen por primera vez lo tomen por un científico, cuando en realidad es una persona común y corriente. Imaginemos que llevamos a nuestro amigo a una conferencia científica y frente a más de 1.000 asistentes, Gaspar comienza una disertación en donde recorre con gran precisión las 20 investigaciones más importantes de Albert Einstein. Sin duda dejaría asombrado a todos. Además, Gaspar no solo es capaz de hablar por horas y horas sobre sus temas preferidos, sino que también responde casi cualquier pregunta del público: ¿Qué similitud tiene la relatividad especial y la relatividad general? No es necesario que Einstein haya escrito precisamente sobre esto para que Gaspar conteste, porque además de tener una excelente memoria, tiene también una asombrosa capacidad para relacionar y conectar el conocimiento ya memorizado. G.P.T puede buscar patrones y similitudes entre los distintos papers que estudió y responder preguntas específicas sobre contenido, explicar conceptos, hacer resúmenes, comparaciones y contrastes dentro del mismo conocimiento. Entre aplausos del público, el consenso de todos los asistentes es que Sí, Gaspar es una persona de gran inteligencia. ¿Es el nuevo científico top del planeta?
¿Es inteligente GPT?
Hablemos directamente de los modelos de lenguaje (LLM), como GPT4. Estos modelos no solo han sido entrenados con todas las investigaciones y textos de Albert Einstein, sino que con una buena parte del conocimiento escrito de la humanidad: publicaciones científicas, libros, revistas, artículos, diccionarios y enciclopedias. Se usaron también millones de medios digitales: Wikipedia, portales de noticias, entrevistas, Twitter, Reddit, entre otros. Todo esto, a lo alto y ancho de los distintos idiomas, culturas, estilos y épocas disponibles en los registros de la humanidad. Por último, se sumaron también lenguajes de programación y todos los repositorios de código disponibles en internet. Con todo este conocimiento a disposición, los modelos como GPT4 son capaces de contestar a prácticamente a cualquier pregunta que hagamos demostrando un absoluto dominio en todos los temas.
¿Existe inteligencia entonces en los LLM? Si queremos compararlos con la inteligencia humana la respuesta es Sí y No. Las personas utilizamos en nuestro día a día una mezcla de memoria y razonamiento. Por un lado, la memoria nos permite almacenar información, aprender sobre hechos específicos y reconocer patrones. Es especialmente útil cuando nos enfrentamos a problemas que ya hemos experimentado en el pasado. En estos casos, podemos recuperar desde nuestra memoria cualquier herramienta o patrón almacenado que nos sirva para avanzar. Por ejemplo, cuando aprendemos a sumar en el colegio, básicamente lo que aprendemos es un patrón o “programa” de suma que guardamos en la memoria, y podemos aplicarlo en el futuro cada vez que queremos sumar dos números. En resumen, aprendemos a hacer ciertas tareas. En este sentido, gran parte de la inteligencia humana se desarrolla a través de la memoria, a través de habilidades que adquirimos en buena medida en el colegio y en la universidad.
Si solo nos basamos en esto, es posible afirmar que los LLM son inteligentes, porque son capaces de utilizar su memoria (creada a través de su entrenamiento) para resolver problemas y contestar a preguntas. Mientras los patrones o “programas” necesarios hayan sido parte de su entrenamiento, los modelos pueden utilizarlos para resolver situaciones similares presentadas por el usuario. De la misma forma que podemos decir que una persona que sabe sumar y multiplicar es más inteligente que una persona que no sabe hacerlo, podemos afirmar que los LLM son inteligentes en comparación con otros modelos más simples.
Sin embargo, a la hora de compararlos con la inteligencia humana, aún sigue faltando un componente fundamental.
Razonamiento
El razonamiento es la capacidad que tenemos los humanos para utilizar nuestra memoria y resolver problemas nuevos. Involucra lógica, inferencia e interpretación. El razonamiento humano permite la adaptación a nuevas situaciones y escenarios, de manera creativa y flexible (novelty). Por ejemplo, para ir de vacaciones debemos razonar: buscar un destino considerando factores como el clima, la distancia y el presupuesto. Luego reservar vuelos y alojamientos comparando precios y horarios. Si surge un imprevisto, como un vuelo cancelado, debemos buscar y evaluar rápidamente las alternativas y decidir la mejor opción, como cambiar de aerolínea o ajustar el itinerario.
Múltiples estudios recientes han demostrado que los más grandes y sofisticados modelos como GPT4 no son capaces de razonar (https://arxiv.org/abs/2406.02061) o de planificar tareas al nivel de un humano (https://arxiv.org/abs/2305.15771, https://arxiv.org/abs/2402.01817). Esto quiere decir que cuando enfrentamos a un LLM a una tarea nueva (ej. algo que no estuvo dentro de la data de entrenamiento, y por lo tanto, no está en la memoria), el desempeño de los modelos cae, por debajo de una persona promedio, incluso por debajo de niños de 5 años. Muchos de los benchmarks más populares utilizados hoy para evaluar la capacidad de los modelos no logran captar la diferencia entre memoria y razonamiento (por ejemplo: MMLU y GSM8K). Solo algunos benchmarks, como ARC (https://github.com/fchollet/ARC-AGI), están ideado para ser más resistente a la capacidad de memorizar, y por lo tanto entregan insights importantes sobre la capacidad de razonamiento de los modelos.
Esto puede ser difícil de creer y/o comprobar para quienes hemos utilizado herramientas como ChatGPT, en donde muchas veces pareciera existir razonamiento y planificación de parte de los modelos. Esta ilusión de razonamiento ocurre principalmente por dos razones. La primera razón se debe al gran Corpus de data utilizado para entrenar los modelos, lo que hace difícil encontrar temas o ejemplos que no hayan sido parte del mismo entrenamiento. Por ejemplo, cuando le pedimos al modelo que escriba una función en Python para encontrar los primeros 100 número primos, lo hace correctamente porque el modelo se entrenó con funciones de código similares (o idénticas en este caso más simple). Sin embargo, nos quedamos con la idea de que el modelo sabe programar cualquier cosa que pidamos. Aun cuando intentamos poner a prueba los modelos en un tema que consideramos novedoso o particular, nos encontramos con que dichos temas también fueron parte del Corpus de entrenamiento, y el modelo nos sorprende. Existe la idea de que, si entrenamos los modelos con suficiente data como para cubrir todos los posibles campos del conocimiento humano, sería suficiente para obtener un herramienta definitiva. ¿Para qué querríamos mas? Si un usuario necesita hacer una tarea específica, un modelo entrenado con todas las tareas específicas que hemos realizado como humanidad bastaría ¿o no? ¿Para qué necesito el razonamiento? Sin embargo, sin importar el tamaño del modelo o del Corpus utilizado para el entrenamiento, al modelo aún le faltaría la capacidad para adaptarse a situaciones nuevas. Y como humanidad, creamos situaciones nuevas cada día.
La segunda razón por la que tenemos la ilusión de estar frente a un modelo que puede razonar también tiene relación con el Corpus de entrenamiento, pero de una manera distinta. En los millones de párrafos de texto utilizados para entrenar un LLM, hay suficientes muestras o ejemplos de razonamiento como para que, ante ciertos problemas de lógica o planificación, el modelo pueda recurrir a un esquema de razonamiento “memorizado”. Es decir, se guarda una especie de receta lógica en la memoria. Pero “aprender a razonar” a través de miles de ejemplos (razonar de memoria) no es lo mismo que razonar, algo que se puede ilustrar fácilmente con un ejemplo: Existe un acertijo muy conocido sobre un pastor que debe cruzar un rio, junto a un lobo, una oveja y un fardo de pasto. El pastor tiene un bote en donde solo caben 2 pasajeros, por lo que solo podría viajar con 1 de los tres a la vez (o el lobo, o la oveja o el pasto), sin embargo, si el pastor deja al lobo con la oveja solos, el lobo se come a la oveja (lo mismo la oveja con el pasto). Este acertijo tiene una solución lógica, que consiste en ir y volver (hacer varios viajes) escogiendo cuidadosamente a quien llevar, para que los animales no se coman. Cuando le preguntamos a GPT4 que nos ayude a solucionar una variación simple del mismo acertijo (de nuevo, novelty), pero solo con la oveja, esta es la respuesta:
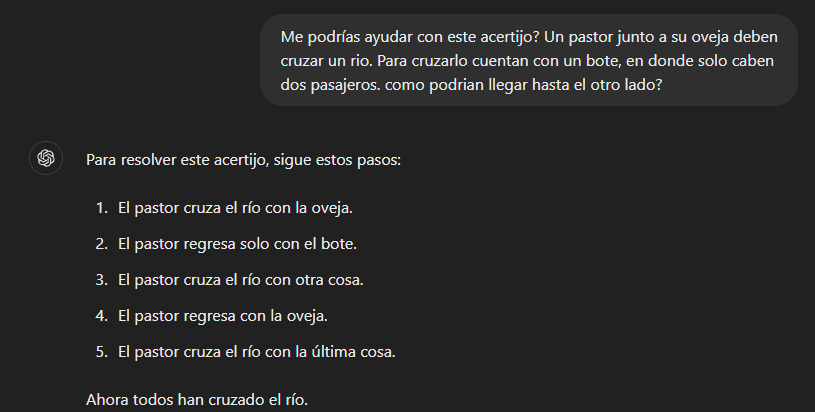
Por un lado, es claro que la respuesta es incorrecta. La respuesta de GPT4 demuestra que el acertijo original fue parte de la data de entrenamiento del modelo, y ante nuestro nuevo acertijo, el modelo recurre a este “razonamiento memorizado” para intentar resolver nuestra nueva versión. Sin embargo, pese a que nuestro nuevo acertijo lo podría resolver un niño de 10 años (la solución es tan simple como: cruzar el rio con la oveja), el modelo utiliza una receta que no sirve, y se equivoca al dar la respuesta. En resumen, el modelo de lenguaje no sabe razonar, intenta razonar “por memoria” y se equivoca.
Hype, GPT5 y el futuro de la inteligencia artificial
¿Importa tanto si los LLM actuales representan solo parcialmente el espectro de inteligencia humana? Depende de a quien le preguntamos. Hoy estamos ante una ola de Hype extrema en lo que respecta a inteligencia artificial. Seguramente que parte de esto se debe a una sobreestimación de las capacidades actuales que tienen los LLM, que como hemos explicado, aparentan ser más inteligentes y capaces de lo que realmente son. En esto las redes sociales y la viralización del tema no ha ayudado mucho. Para los inversionistas y empresas que pueden obtener una ganancia de esto, las altas expectativas y las exageraciones pueden ayudar al negocio, atrayendo más inversión e interés general de los usuarios. Ahora bien, para ser justos una gran parte de Hype también es real y justificable. Si miramos la capacidad de los LLM para memorizar y asociar información en su propio mérito, esta funcionalidad ya es revolucionaria por si sola. Los casos de uso ya desarrollados parecen ser sacados de una película de ciencia ficción, y presentan un potencial gigante para todos los ámbitos de la actividad humana. Es decir, la utilidad y valor de los LLM no está en discusión.
Sin embargo, desde el punto de vista científico (la comunidad que desea avanzar, para acercarnos a lo que es la inteligencia humana), varios líderes de opinión aseguran que no será posible avanzar mucho más con la actual arquitectura de Transformers. Por ejemplo, para Francois Chollet, investigador de IA en Google, los modelos como GPT4 estarían llegando a un límite y no importa mucho si para el nuevo modelo GPT5 se sigue invirtiendo en tamaño y/o data de entrenamiento. Los modelos no serán más inteligentes ni capaces de razonar por ser más grandes, solo ganarán más memoria. Por otro lado, Yann LeCun, uno de los líderes de opinión en IA e investigador de Meta, les aconseja a los jóvenes no seguir investigando LLMs, y en cambio, recomienda buscar nuevas fronteras de investigación que ayuden a destrabar las limitaciones actuales. Opiniones más polémicas hablan de que el Hype de los LLM ha capturado tanto la atención de empresas, academia y público general, que han “consumido todo el oxígeno” disponible, perjudicando a otras ramas de investigación que podrían finalmente llevarnos a la Inteligencia Artificial General o AGI.
Finalmente como última reflexión, mientras esperamos la próxima entrega de OpenAI con GPT5 o de una nueva arquitectura revolucionaria de modelos, es fundamental que desde ya miremos con detención nuestros propios trabajo y actividades. Que a los modelos aún les falte una pieza importante no significa que podamos menospreciar su capacidad transformadora, a través de lo que ya pueden ofrecer. Podríamos decir que los LLM tiene una fracción de nuestras habilidades mentales, pero ya con esa fracción son capaces de superarnos en múltiples ámbitos. Esto significa que nuestros roles y nuestros trabajos van a evolucionar inevitablemente. ¿Cuánto de nuestro día a día corresponde a tareas más bien mecánicas y repetitivas? ¿Qué porcentaje de nuestra jornada la dedicamos a aplicar un “programa” o rutina aprendida que está en nuestra memoria? Las respuestas a estas preguntas nos van a ir anticipando las oportunidades (y riesgos) que podemos tener en un futuro próximo.

