

Hoy en día estamos viviendo una nueva era de aplicaciones de inteligencia artificial que no habíamos imaginado a principios de los 2000. De seguro has escuchado de la herramienta de Google llamada Bard, que puede ayudarte tomando apuntes, resumiendo y haciendo presentaciones de reuniones. O, quizás, ya has seguido el trend de crear imágenes de tu mascota en Microsoft Bing, potenciado por DALL-E 3. Detrás de todas estas funcionalidades se encuentran los foundation models, que han cambiado el paradigma de las tareas que se pueden realizar con inteligencia artificial. En este blog te introduciremos qué son los foundation models, algunos datos sobre su arquitectura y aplicaciones exitosas.
¿Qué son los foundation models?
En palabras simples, son modelos que se entrenan con una gran variedad y cantidad de datos, y pueden adaptarse a realizar múltiples tipos de tareas. Por ejemplo, algunas funciones que puede realizar el famoso modelo GPT-4 son resúmenes de texto, análisis de sentimiento, generación de códigos y redacción de publicaciones.
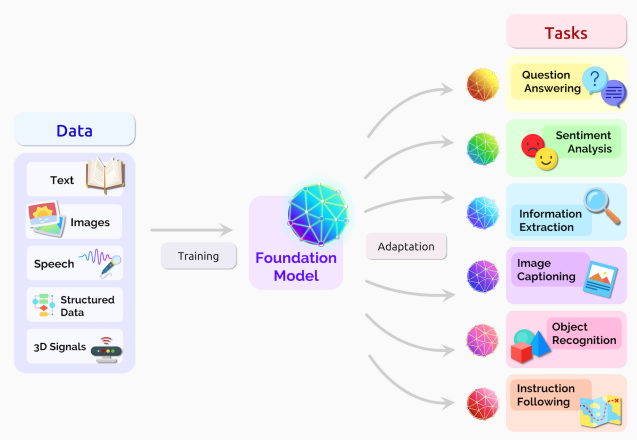
En la Figura 1 se ilustra lo mencionado: un foundation model recibe grandes volúmenes de datos, incluyendo textos e imágenes, y almacena aprendizajes que les permiten desempeñarse en múltiples tareas. Por lo general, la etapa de entrenamiento ya viene desarrollada por grandes compañías tecnológicas.
Para que un foundation model sea exitoso en una tarea específica, debe pasar por una etapa de alineamiento, en la que lo adaptamos a la labor que deseamos que desempeñe. He aquí una de sus grandes ventajas: no necesitamos volver a entrenarlo desde el inicio para que cumpla una función distinta.
¿Cómo hemos llegado a los foundation models?
Cada década ha tenido sus enfoques favoritos y disruptivos. En la Figura 2 se puede apreciar a grandes rasgos esta evolución.

A principios de siglo predominaban los modelos de Machine Learning tradicionales supervisados, que buscaban cumplir con una tarea de predicción específica. Este enfoque se realizaba con datos tabulados, que implican mucho trabajo humano para generar tablas con múltiples características.
En la década del 2010, ganó atención el área de Deep Learning y las nuevas arquitecturas de redes neuronales. Este enfoque le dio prioridad al aprendizaje de características y generación de espacios semánticos, o sea, espacios en los que elementos similares se encuentran cercanos. A su vez, permitió un avance en el uso de bases de datos diferentes a tablas, como imágenes, con resultados significativamente mejores.
Bajo este contexto, surgieron los modelos Seq2Seq, que parecían ser la solución a tareas que se llevaban trabajando desde inicios de siglo. Estos modelos son redes neuronales utilizadas, inicialmente, en el procesamiento de lenguaje natural. Tienen buenos rendimientos en tareas de resumir o traducir oraciones. Sin embargo, presentan problemas de eficiencia computacional y de predicción con secuencias muy largas de input.
Parecía que se había llegado a cierto límite en el área. Mientras se ocuparan secuencias de datos pequeñas y medianas todo funcionaba bien. Fue en ese entonces cuando Google dio uno de los primeros pasos en la actual revolución de aplicaciones de inteligencia artificial: propuso una nueva arquitectura de red neuronal que buscaba solucionar varios de los problemas presentes en los modelos. Esta arquitectura se denomina Transformer y es un avance técnico clave que permitió llegar a los foundation models que usamos hoy en día.
Arquitectura Transformer
En el año 2017, un equipo de Google publicó el paper “Attention Is All You Need” en el que introducen la arquitectura Transformer junto a varios resultados interesantes en tareas de traducción de idiomas [2]. Algunos puntos relevantes que mencionan son los siguientes:
- La arquitectura Transformer es una arquitectura de red simple basada únicamente en mecanismos de auto-atención, que identifican las dependencias existentes dentro de las secuencias de input. No utilizan redes neuronales convolucionales ni recurrentes, que correspondían a las más utilizadas y con mejores rendimientos.
- Los modelos que utilizan la arquitectura Transformer requieren costos y tiempos de entrenamiento significativamente menores en comparación a modelos que utilizan otros tipos de arquitectura.
- Adicionalmente, los modelos con arquitectura Transformer tienen rendimientos más altos en tareas de traducción de idiomas que los modelos que se usaban. De hecho, superaron los mejores resultados existentes.
Los puntos descritos resolvían problemáticas presentes en las redes neuronales más usadas, como la baja eficiencia computacional y los altos costos de entrenamiento. El nombre del paper, “Atención es todo lo que necesitas”, apunta a lo que se considera el éxito de los Transformers: las capas de auto-atención.
Simplificación de la estructura Transformer
En la siguiente imagen (Figura 3) se expone una simplificación de la arquitectura Transformer, con una composición encoder-decoder. El encoder procesa la secuencia de entrada y genera una representación vectorial que almacena información relevante del input. El decoder recibe los vectores del encoder y los procesa para generar una salida de acorde a la tarea que se busca cumplir.
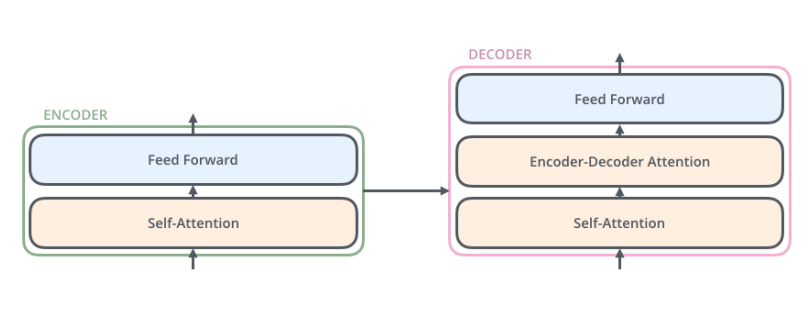
Para el caso de traducción de idiomas, la estructura encoder-decoder busca aprender características eficientes de las secuencias de input que permitan construir la secuencia de output en otro idioma. La importancia de las capas de auto-atención es que permiten identificar las dependencias dentro de una secuencia.
Para comprender mejor cómo funcionan estas capas, podemos pensar en la forma en la que nos comunicamos. Al hablar con alguien, importa el orden en el que formulamos las oraciones para que los demás nos puedan entender. Las capas de auto-atención precisamente permiten identificar cómo depende cada elemento de una secuencia del resto.
Ejemplos de foundation models
Los foundation models actuales contienen internamente variaciones inspiradas en la arquitectura transformer. A continuación, se detallarán algunas aplicaciones exitosas.
1) BERT (Bidirectional Encoder Representations from Transformers)
Es un modelo de lenguaje introducido el año 2018 por Google. Está basado en la arquitectura de transformer y representó un aumento significativo en el rendimiento de los modelos de lenguaje y procesamiento de lenguaje natural. Algunas de las funciones a las que se puede adaptar son:
- Clasificación de texto (por ejemplo, clasificación de spam)
- Análisis de sentimiento
- Resumen de textos
- Sistemas de preguntas y respuestas
2) GPT-4 (Generative Pre-trained Transformer 4)
De seguro lo has escuchado. Es un modelo grande de lenguaje creado por OpenAI y lanzado en marzo del presente año. Tiene la característica de ser multimodal: puede recibir inputs de tipo texto e imagen. Se adapta a realizar múltiples tareas de generación de texto, en las que obtiene desempeños muy altos. Además de las tareas que cumple BERT, es utilizado en generación de publicaciones, corrección de redacciones, análisis de textos de imágenes y generación de códigos de programación simples.
3) DALL-E 3
Es un modelo de conversión de texto a imagen desarrollado por OpenAI y lanzado en octubre de 2023. A partir de una descripción, puede generar imágenes en múltiples estilos. Por ejemplo, puedes pedirle un objetivo con una representación hiperrealista o como animación de Disney Pixar.
3) OpenAI Codex
Descendiente de GPT-3, está especializado en tareas de generación y completación de códigos de programación a partir de lenguaje natural.
Herramientas basadas en foundation models
Existen herramientas de diversos ámbitos que han incorporado estos modelos con resultados exitosos. Algunas de ellas son:
- ChatGPT: Tiene integrado versiones del modelo GPT para ser usado como asistente virtual. La versión Plus integra DALL-E 3, por lo que también puede generar imágenes.
- GitHub Copilot: Es una herramienta impulsada con GPT-4 y Codex. Su objetivo es asistir en entornos de desarrollo mediante el autocompletado de códigos de programación.
- Microsoft Copilot: Es el asistente virtual de Microsoft. Desde marzo del presente año integra GPT-4, facilitando tareas de generación de contenido creativo, traducción de idiomas, edición de documentos y completación de códigos de programación.
- Khanmigo y Duolingo Max: Son herramientas de aprendizaje que integran GPT-4 para servir como tutores virtuales. GPT-4 facilita el aprendizaje al mejorar la interacción con el usuario al momento de explicar contenidos.
- Auto-GPT: Es un agente autónomo potenciado por GPT. Dado un objetivo en lenguaje natural, lo divide en subtareas hasta cumplir la meta. Tiene la capacidad de buscar en la web sin intervención humana.
Conclusiones
Los foundation models representan un hito importante en la nueva era de aplicaciones de inteligencia artificial. Estos modelos son entrenados con una gran variedad de datos, por lo que almacenan múltiples conocimientos. Lo anterior es posible gracias a su arquitectura compuesta por múltiples capas de auto-atención, que son eficientes computacionalmente y tienen la capacidad de identificar las dependencias internas de las secuencias de input.
Para que un foundation model sea efectivo en una tarea específica, debe pasar por una etapa de alineamiento enfocada a la labor a desempeñar. No debe ser entrenado nuevamente. Por ejemplo, el modelo BERT ha sido adaptado para clasificar texto, realizar resúmenes y análisis de sentimiento.
Algunas herramientas con desempeños exitosos son ChatGPT, Microsoft Copilot y Khanmigo. Todas ellas integran el modelo GPT para que se desempeñe como asistente virtual con los que puedes comunicarte como si fueran personas. En Notus entendemos a cabalidad estas, y muchas otras, herramientas de Inteligencia Artificial. Con ellas realizamos proyectos y aplicaciones para diversos servicios de las empresas, elevando su rentabilidad. ¿Tienes algún problema que podamos resolver mediante la aplicación de los foundation models? Conversemos.
[Lista de fuentes utilizadas]

