

Por Ignacio Fibla, Data Scientist en Notus
¿Data Scientist? Probablemente uno de los títulos de trabajo más recientes y poco conocidos que viene recién llegando con la transformación digital de estos últimos años. En realidad no es algo tan nuevo, la ciencia de datos tiene raíces en disciplinas clásicas como la estadística, el análisis cuantitativo y la investigación operativa, donde profesionales con estas habilidades han estado resolviendo problemas complejos desde hace décadas. El área de Data Science es el corazón de un sin fin de elementos que ocupamos, desde las series y películas que te recomienda Netflix, hasta las rutas que te propone Google Maps para llegar más rápido a tu destino.
Una carrera que está totalmente de moda. Basta con buscar un poco para notar que muchas universidades, institutos y plataformas de formación ofrecen magísteres, diplomados, cursos e incluso carreras completas en el área de Data Science. Pero, siendo una carrera tan novedosa y requerida, ¿qué hace realmente un Data Scientist? Tranquilo, en Notus nos preguntan lo mismo todo el tiempo. Es por eso, que quisimos responder esta gran pregunta de forma simple y concreta, mostrando qué hay detrás del rol, qué problemas aborda y cómo su trabajo genera impacto real en las decisiones del día a día.
¿Qué hace un Data Scientist?
Vamos al grano. Un Data Scientist es la persona encargada de analizar grandes volúmenes de datos y transformarlos en información útil para la toma de decisiones, apoyándose en argumentos sólidos respaldados por la estadística. Para lograrlo, combina herramientas estadísticas con modelos de predicción y clasificación, programación y técnicas de visualización de datos, con el objetivo de comunicar hallazgos de forma clara y generar impacto real en el negocio. Si aún no te queda claro, te dejo el siguiente ejemplo.
Imagina que en tu empresa te asignan la misión de anticipar la demanda del próximo mes y para ello cuentas con distintos tipos de información. Entre estos datos se encuentran el historial de ventas de los últimos años, los precios y promociones aplicadas, los niveles de stock, el comportamiento de los clientes, la estacionalidad del negocio e incluso variables externas como feriados o condiciones climáticas.
Sin el apoyo de herramientas ni métodos adecuados, enfrentar esta misión significa pasar días revisando planillas y analizando información fila por fila con el objetivo de detectar patrones a simple vista. Sin embargo, a medida que el volumen y la complejidad de los datos aumentan, este enfoque manual se vuelve poco eficiente y difícil de escalar.
En este contexto, la ciencia de datos aparece como una solución natural, ya que permite analizar grandes volúmenes de información de forma rigurosa y sistemática. A través de análisis exploratorios, modelos estadísticos y técnicas de aprendizaje automático, es posible estimar la demanda futura con mayor precisión y lograr la misión que se nos asignó en un principio.
Pero, el trabajo de Data Science no termina ahí. La predicción es solo una de sus múltiples aristas y, en la práctica, es posible entregar mucho más valor del que normalmente se imagina. Desde la mirada de un Data Scientist, se puede aportar evidencia estadística que permita identificar qué variables influyen realmente en la demanda futura, así como evaluar si una estrategia comercial, como promociones, segmentación de clientes o sistemas de recomendación, fue efectiva en su implementación. En este contexto, las posibilidades de aplicación son prácticamente infinitas.
El proceso de la ciencia de datos
Al igual que todas las ciencias, la ciencia de datos sigue un proceso meticuloso y sistematizado, lo que permite que los resultados sean replicables y demostrables. Este proceso cuenta con etapas bien definidas que ayudan a ordenar el análisis según la pregunta o hipótesis que se desea abordar. Este proceso puede ser resumido en la siguiente figura.
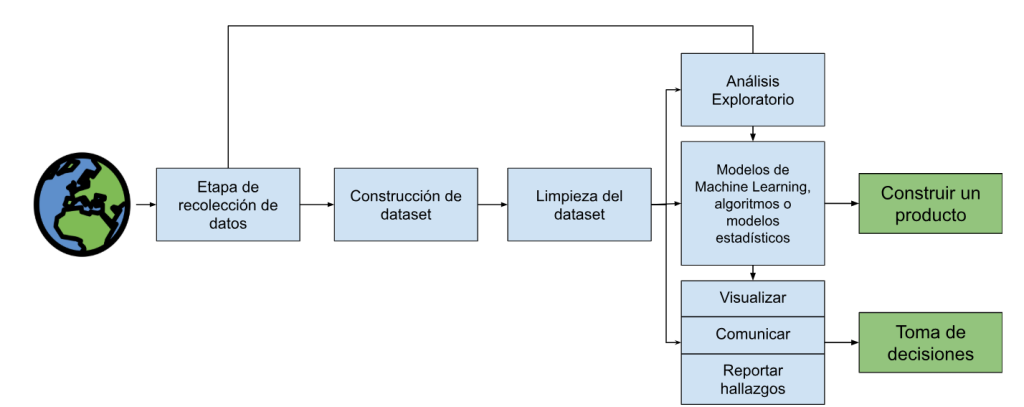
Todo comienza en el mundo real, donde surge la pregunta que queremos responder y la hipótesis que deseamos contrastar. En este contexto, las actividades cotidianas de personas, empresas y sistemas generan datos de forma constante. En la etapa de recolección, esta información se obtiene en su forma más cruda, comúnmente conocida como datos sin procesar. En este punto, los datos suelen estar incompletos, desordenados o contener errores, por lo que aún no son directamente utilizables para el análisis.
Toda la información recolectada da origen al dataset del proyecto. A partir de los datos obtenidos, se construyen distintas tablas más estructuradas, organizadas en formatos comprensibles, con encabezados claros y una primera lógica de ordenamiento que permita su posterior procesamiento.
El siguiente paso consiste en procesar y limpiar los datos, transformándolos en un formato adecuado para su estudio. Este trabajo incluye integrar múltiples fuentes de información, corregir inconsistencias, tratar valores faltantes y asegurar la coherencia de los datos, sentando las bases para un análisis confiable.
Una vez que los datos están limpios, se realiza el análisis exploratorio, cuyo objetivo es comprender el comportamiento de la información, identificar patrones relevantes, detectar anomalías y validar supuestos iniciales. Esta etapa es clave, ya que permite evaluar si los datos disponibles son suficientes para responder la pregunta planteada o si es necesario volver a etapas anteriores para recolectar información adicional que complemente el análisis.
Con este entendimiento previo, es posible avanzar hacia la aplicación de modelos estadísticos y algoritmos de aprendizaje automático. Estos modelos permiten explicar fenómenos, realizar predicciones o clasificar información según el problema planteado. En esta etapa, el rol del Data Scientist puede tomar múltiples formas, desde el desarrollo de sistemas de recomendación como los utilizados por Spotify o Netflix, hasta modelos de pronóstico de demanda como el del ejemplo anterior.
Sin embargo, el proceso no termina en la construcción del modelo. Los resultados deben ser comunicados de manera clara y efectiva a través de visualizaciones y reportes que permitan generar insights accionables. Estos reportes no son aislados, sino que están directamente respaldados por las etapas anteriores, especialmente por el análisis exploratorio, lo que garantiza que las conclusiones estén sustentadas en evidencia estadística y no solo en resultados numéricos.
Finalmente, este flujo puede derivar en la construcción de productos de datos, como dashboards interactivos, sistemas de recomendación o modelos integrados en procesos operacionales. De esta forma, el ciclo se cierra al generar impacto directo en el mundo real y al mismo tiempo alimentar nuevas iteraciones del proceso de ciencia de datos.
Proyectos de un Data Scientist
En Notus hemos abordado un sinfín de proyectos asociados a Data Science, muchos de ellos similares a los que hemos mencionado a lo largo de este blog. Un ejemplo son los proyectos de predicción y estimación, los cuales abarcan una amplia variedad de escenarios. Estos van desde casos más habituales, como la predicción de demanda o ventas de una sucursal, hasta problemáticas más específicas, como estimar la cantidad de salmones que podrían presentar ciertos defectos en un proceso productivo.
Otro tipo de proyectos a los que nos enfrentamos con frecuencia corresponde a problemas de clasificación y detección, los cuales implican el desarrollo de algoritmos y modelos capaces de identificar si un elemento pertenece a un determinado grupo o categoría. Este tipo de desafíos es muy diverso e incluye aplicaciones como la detección de fraudes bancarios, la identificación de spam, la segmentación de clientes, entre otros.
Finalmente, existen proyectos particularmente atractivos que combinan distintos enfoques, integrando modelos de predicción y clasificación con el objetivo de comprender un contexto más profundo que va más allá del simple hecho de predecir o clasificar. Un ejemplo claro de esto son los sistemas de recomendación, ampliamente utilizados por plataformas de retail y streaming, los cuales, a partir del análisis de grandes volúmenes de datos, generan recomendaciones personalizadas en función de los productos que un usuario ha comprado o de las canciones, películas o series que ha consumido o calificado previamente.
Otro ejemplo relevante de este tipo de proyectos corresponde a la evaluación de estrategias comerciales, donde, mediante análisis exploratorio y modelos de predicción, es posible medir qué acciones tienen un mayor impacto en las ventas. Por ejemplo, se puede analizar si la incorporación de una promoción genera un cambio significativo en el comportamiento de compra y en los resultados de la empresa.
Ser Data Scientist en Notus
La era digital nos permite acceder fácilmente a una enorme cantidad de datos que, en muchos casos, no se utilizan o no se aprovechan en su real potencial. Sin embargo, cuando estos datos son analizados por un Data Scientist con las herramientas adecuadas y un razonamiento correcto, pueden transformarse en una fuente significativa de valor para la empresa.
En Notus, nos especializamos fuertemente en convertir datos en decisiones, aplicando analítica avanzada y modelos basados en evidencia para resolver problemas reales del negocio. Ahora que ya conoces qué hace un Data Scientist y por qué su rol es clave en el contexto actual, te invitamos a descubrir cómo desde Notus ayudamos a las organizaciones a aprovechar sus datos y transformarlos en ventajas competitivas. Conversemos.

