

Por Ignacia Córdova
¿Sabes cómo hacen las aseguradoras para estimar los costos esperados de las reclamaciones de tus seguros y así cobrar una póliza determinada? Probablemente utilizan modelos estadísticos. Los modelos estadísticos son una forma simple de representar los datos de la realidad y, con esta información, hacer predicciones de lo que podría suceder en el futuro. Para esto, se pueden utilizar distribuciones de probabilidad con el fin de hacer pruebas de hipótesis y, finalmente, ayudar en la toma de las decisiones respectivas. Entonces, las empresas aseguradoras utilizan datos de clientes con características parecidas a las tuyas y revisan cuántos han sido tus gastos, para así, estimar cuánto cobrar en el seguro y obtener una ganancia.
¿Cuáles son las partes de un modelo estadístico?
Los modelos estadísticos tratan de establecer una relación entre variables dependientes y variables independientes. Las variables independientes son las que queremos predecir, explicar o describir y, generalmente, se encuentran en el eje X de los gráficos. Las variables dependientes son las que se usan para predecir, explicar o describir a las variables independientes y las pueden encontrar con mayor facilidad en el eje Y. Cualquiera de las variables nombradas anteriormente pueden ser cuantitativas o cualitativas.
También, en este tipo de modelos podemos encontrar parámetros, que son la forma de vincular a las variables independientes con las dependientes, por medio de una ecuación matemática. Por otro lado, los residuos o errores son la distancia entre los puntos que representan los datos y el modelo, descrito por una línea. Estos nos informan de la variabilidad que tienen los datos que no ha sido capturada por la línea del modelo. Entonces, mientras los residuos sean más pequeños, el modelo representa mejor a los datos proporcionados.
La forma en la que los modelos estadísticos logran relacionar todas estas partes es a través de ecuaciones matemáticas, con el fin de codificar la información que se puede sacar de los datos. Uno de los ejemplos más comunes es la regresión lineal simple. Este explica la relación entre Y (variable dependiente) y sólo una X (variable dependiente). La fórmula para una regresión lineal común es la siguiente:
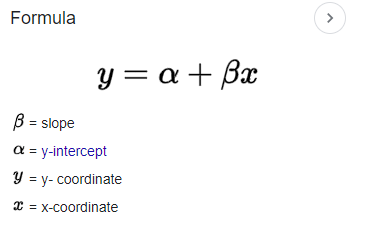
En ella, relacionamos los dos tipos de variables (X e Y) con el intercepto (Alpha) y la pendiente (Beta).
¿Cómo realizar un modelo estadístico y cuáles son los tipos que podemos encontrar?
Los modelos estadísticos se pueden encontrar agrupados en 2 tipos:
- Modelos Lineales (LM): Estos predicen un objetivo basándose en relaciones lineales entre éste y los predictores. Ejemplos de estos son los modelos de regresión, ANOVA y ANCOVA.
- Modelos Lineales Generalizados (GLM): En ellos la variable dependiente se relaciona de forma lineal con los factores y las otras variables, mediante una función llamada función de enlace. Además, este modelo tiene la característica que permite que la variable dependiente tenga una distribución no normal. Ejemplos de estos modelos son los modelos de respuesta binomial o de poisson, modelos log-lineales y los modelos de supervivencia.
Ya conociendo las diferentes agrupaciones y partes del modelo podemos comenzar a construirlo. Para esto, precisamos realizar los siguientes pasos:
- Definir las variables dependientes e independientes y los objetivos: Esto permite elegir el tipo de modelo más adecuado según el diseño experimental.
- Seleccionar la hipótesis: Esta tiene que reflejar y hacer referencia al comportamiento aleatorio del modelo.
- Estimar el modelo: Se obtienen las estimaciones de los parámetros y de los residuos.
- Ajustar el modelo: Nos permite concluir si el modelo obtenido tiene capacidad explicativa, es decir, si las variables dependientes pueden explicar el comportamiento de la respuesta.
- Realizar una comparación entre modelos: Se debe construir un modelo parsimonioso, es decir, un modelo sencillo (con la cantidad justa de parámetros) que explique el comportamiento de la respuesta. Para ello, debemos comparar modelos con más o menos parámetros para encontrar la cantidad necesaria de ellos sin comprometer la bondad de ajuste.
- Validar el modelo: Esto se basa en verificar si los residuos cumplen con la hipótesis. Acá se puede aceptar el modelo propuesto o rechazar. Si se rechaza se debe proponer un nuevo modelo.
- Realizar la predicción: En este paso se utiliza el modelo para predecir el comportamiento de la respuesta.
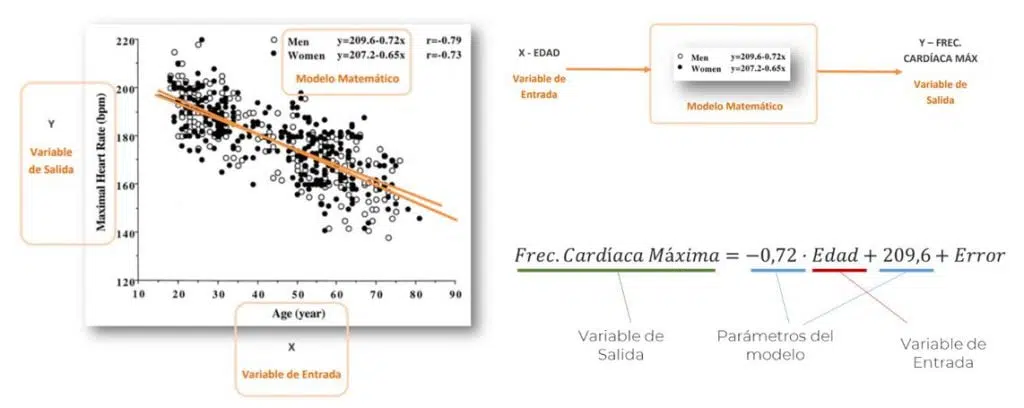
En Notus, mediante un modelo estadístico, ayudamos a Lipigas, uno de los principales distribuidores de gas licuado en Chile, a proyectar su demanda y saber cuánto gas enviar a cada una de sus plantas y qué día realizar estos envíos. Por medio de un software hecho a la medida, se ejecutan los modelos estadísticos de proyección de demanda y se permite al usuario recibir y comprender los pronósticos que este realiza. ¿Tienes algún desafío donde podamos implementar esta herramienta? Conversemos.

