

Por Juan Paul Idrovo y Jorge Ortega, Data Scientists en Notus
Como parte de nuestras iniciativas de innovación y mejora continua, en Notus nos hemos enfocado en varios proyectos pequeños que implementan modelos de lenguaje con el fin de hacer más ágil nuestro trabajo. Para esto, hemos utilizado Modelos de Generación Aumentada de Recuperación (RAG), también conocidos como «chat con tus documentos». Esta tecnología, ampliamente adoptada en la industria, ha sido estudiada y optimizada por la comunidad, lo que permite obtener excelentes resultados sin necesidad de realizar un trabajo extenso de ajuste.
Descripción de los Modelos RAG
Los Modelos RAG, en términos simples, permiten extraer información de tus documentos y utilizarla como base para responder consultas, ofreciendo respuestas más precisas y contextualmente relevantes. Este proceso se organiza en varias etapas clave, cada una contribuyendo a la eficacia del modelo:
- Definir el Modelo de lenguaje a utilizar.
- Limpieza de los datos: se eliminan inconsistencias, ruido y se estandariza la información.
- Dividir los datos en pedazos (chunks)
- Embedding: convierte los datos textuales en vectores numéricos que capturan las relaciones semánticas entre palabras y frases.
- Vectorización: Cuando se presenta una consulta, el modelo recupera los fragmentos de información más relevantes mediante la comparación de estos vectores y genera una respuesta coherente utilizando modelos de lenguaje.
Además, es importante considerar la plataforma en la que se implementará el modelo. Aunque se podría ejecutar directamente desde Python, crear una API permite que sea más «user-friendly«. Esto significa que, en lugar de requerir conocimientos técnicos para interactuar con el modelo, la API facilita su integración en aplicaciones o interfaces más accesibles para los usuarios finales.
Proyecto: motor de búsqueda en archivos pasados con modelos RAG
Es común para una organización almacenar una gran cantidad de documentos cada año y a futuro desear encontrar ciertos datos específicos sin tener que ingresar a cada documento. Una aplicación útil de los modelos de lenguaje es que podemos ajustarlos a nuestros datos y crear motores de búsqueda de información eficientes.
La creación de un motor de búsqueda en archivos propios no solo mejora la eficiencia en la búsqueda de información, sino que también optimiza la gestión de datos, fomenta la colaboración y puede ser adaptado a las necesidades específicas de la organización. En Notus lo hemos implementado para buscar información en nuestro histórico de proyectos pasados.
Los motores de búsqueda se pueden alimentar de distintos tipos de datos, los cuales son cargados (Document Loading), procesados y divididos (Splitting) para ser almacenados en forma de vectores numéricos (Storage), que agilizan el proceso la búsqueda de información. Una vez logrado estos pasos, se puede realizar todo tipo de preguntas, las que desencadenan un proceso de búsqueda (Retrieval) en la información almacenada, hasta generar una respuesta (Output). Este flujo de trabajo se encuentra reflejado en la siguiente imagen:
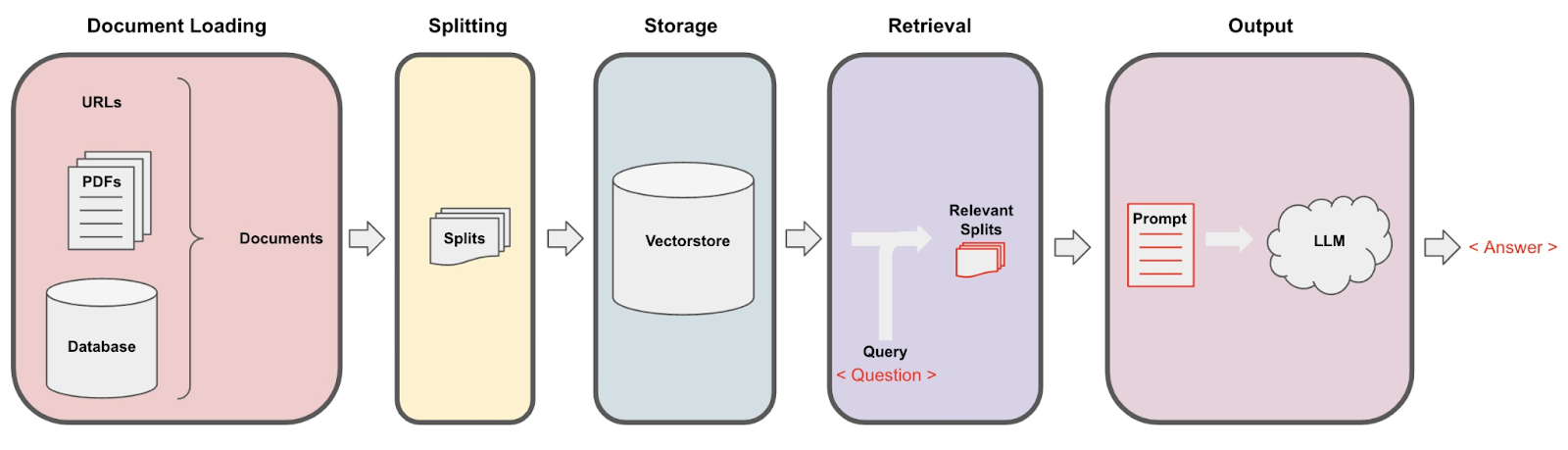
El motor de búsqueda interno de Notus se alimenta de archivos Excel, PDF y presentaciones PowerPoint que contienen información histórica de proyectos que hemos realizado. Estos datos son procesados y almacenados en forma de vectores numéricos (embeddings), como se muestra en la imagen anterior. Esta forma de almacenar datos permite que los procesos de búsqueda de información sean eficientes, a través de modelos de lenguaje.
Los embeddings obtenidos son utilizados por los modelos de lenguaje (LLM), los cuales buscan en ellos y elaboran respuestas. Si bien existen LLM más recientes, para nuestro motor de búsqueda utilizamos GPT 3.5, ya que su funcionamiento está centrado en texto, que es suficiente para nuestro caso. Su sucesor, GPT-4, incluye capacidades multimodales, lo que significa que puede procesar tanto texto como imágenes, ampliando aún más las posibilidades de búsqueda.
Para las etapas de realizar preguntas y obtener respuestas, realizamos una interfaz en Streamlit, que permite interactuar con el LLM de forma amigable, como se muestra en la Imagen 2.
.
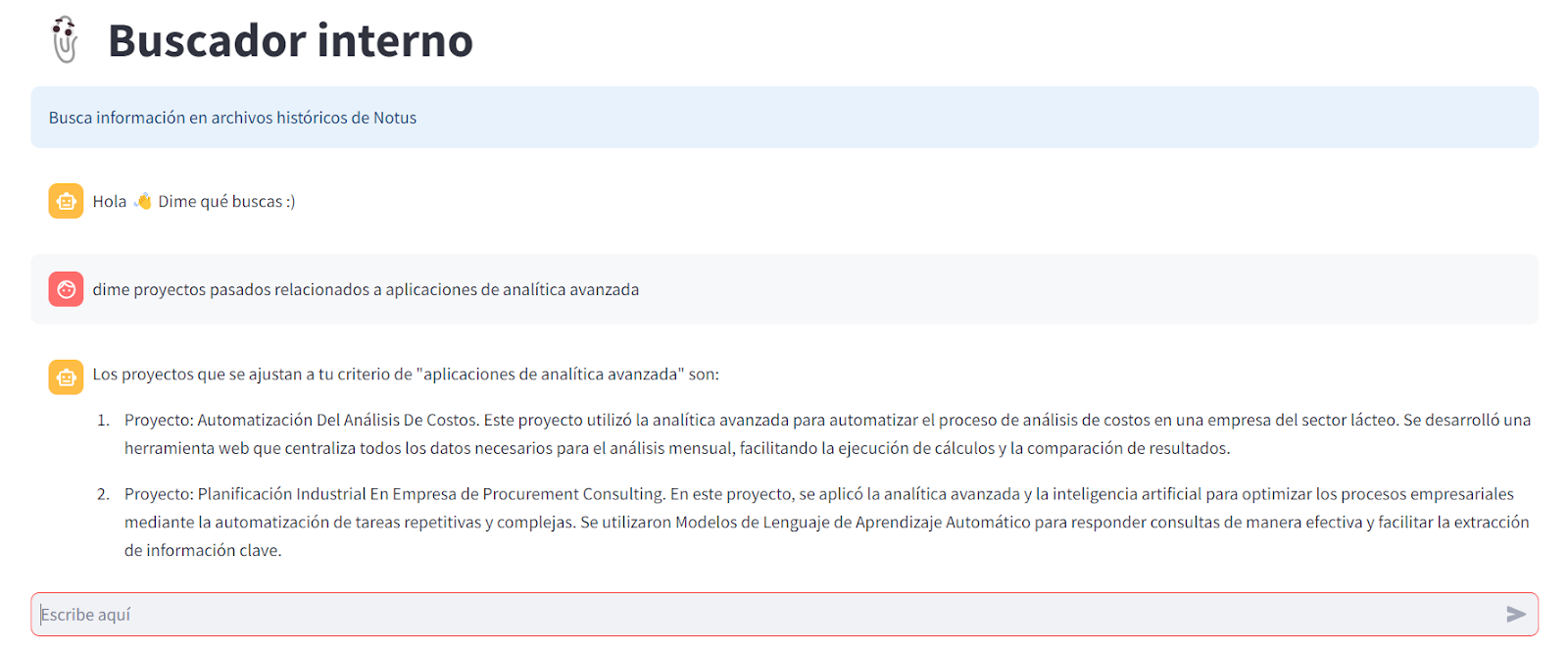
Ingresando preguntas, podemos obtener rápidamente respuestas que se encuentren en nuestros archivos pasados, sin tener que abrir y buscar en cada archivo. En este ejemplo preguntamos sobre los proyectos pasados en los que aplicamos analítica avanzada y nuestra implementación nos respondió, sin tener que buscar y acceder a cada ficha de proyectos pasados.
Proyecto: Ficha Comercial con modelos RAG
Otra herramienta que hicimos para mejorar los procesos internos de Notus fue una aplicación cuyo objetivo es la automatización de las fichas comerciales de proyectos anteriores. Estas fichas antes requerían que los jefes de proyecto buscarán en archivos antiguos, propuestas, presentaciones, etc., un proceso que podía ser agotador y una “pérdida de tiempo”. Con la implementación de Modelos RAG, no solo se ha ahorrado tiempo, sino que se espera que se mejore la precisión y coherencia en la generación de las fichas comerciales, permitiendo que el equipo se enfoque en tareas más estratégicas.
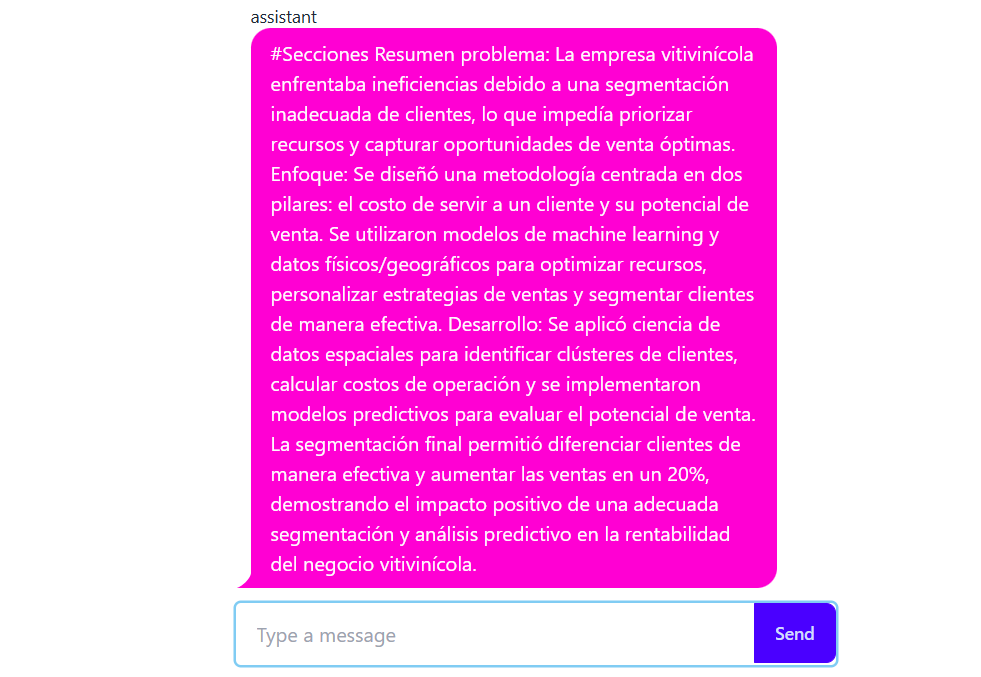
Las fichas consisten básicamente en una diapositiva de PowerPoint con las siguientes secciones: título, problema, enfoque, desarrollo del proyecto, una imagen representativa y conclusiones. Como input se utiliza información recopilada de propuestas de cada proyecto. Esta información se encuentra limpia, ordenada y segmentada en secciones para facilitar el proceso de búsqueda. Sin embargo, la información es bastante breve por lo que podría limitarse a un resumen global del proyecto dejando de lado detalles técnicos.
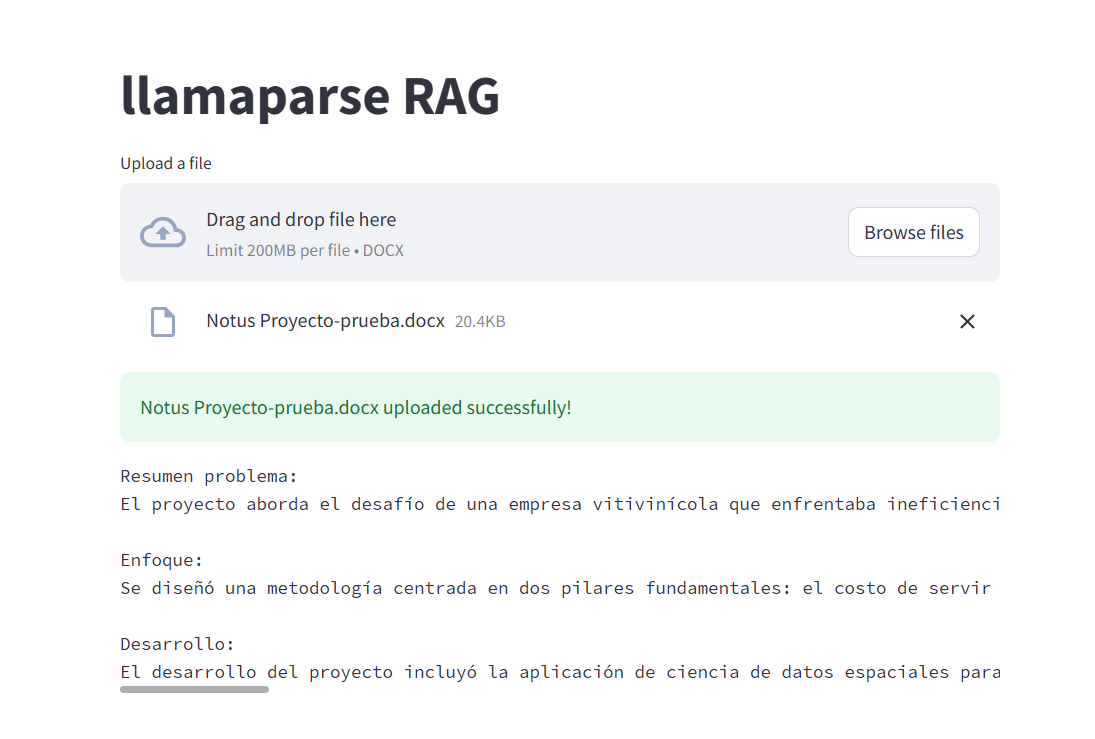
Antes de comenzar seleccionamos el modelo de LLM, como base se utiliza OpenAI, GPT-3.5 Turbo conocido como chat GPT. Como primera iniciativa, dado que contamos con fichas comerciales anteriores, optamos por utilizar técnicas de ingeniería de prompts, específicamente el One-shot Prompting. Esta técnica implica proporcionar un ejemplo de cómo queremos que se genere la respuesta, asegurando que se respete el formato y la extensión de cada sección. Esto se le entrega al modelo dentro de su system message. Finalmente, para interactuar con el modelo se utiliza la librería de Python Streamlit, la cual permite generar una API de manera rápida y fácil. A continuación, se ilustra como se ve la aplicación. Se genera una sección que te permite subir tus documentos, e inmediatamente se realiza la consulta. Como resultado se generan las secciones, en este caso se están generando las secciones de problema, enfoque y desarrollo.
Evolución de un RAG Naive a un Modelo Más Sofisticado
El término «RAG Naive» se refiere al uso predeterminado de un modelo RAG, que suele funcionar de manera excelente siempre y cuando la información esté bien organizada. Sin embargo, en la práctica, esta condición no siempre se cumple. Si se proporcionan archivos desordenados o «basura» al modelo, es probable que el resultado también sea deficiente. Por lo tanto, es crucial limpiar los datos y añadir la metadata adecuada a los archivos para facilitar una extracción de información más precisa.
En respuesta a esta necesidad, ha surgido LlamaIndex, una empresa que se ha dedicado completamente a mejorar este aspecto. Su herramienta más reciente, llamada LlamaParse, ha logrado optimizar no solo la extracción de datos sino también el proceso de segmentación o «chunking«. Cabe destacar que este es un servicio privado: ofrece de manera gratuita hasta 1,000 páginas por día, lo cual es adecuado para proyectos de escala moderada. Sin embargo, para necesidades más extensas, se requiere una suscripción paga.
En el ámbito de embeddings, el modelo predeterminado suele ser el de OpenAI, específicamente Ada. Sin embargo, la investigación en recuperación de información ha experimentado un auge reciente, revelando que modelos como ColBERT son extremadamente eficientes en el manejo de datos. En particular, la iniciativa RAGatouille actúa como un conector entre estos métodos más sofisticados y los enfoques tradicionales, facilitando la integración de estas innovaciones en el proceso de recuperación de información.
Para temas de vectorización existe Groq, la empresa que ha revolucionado el campo de la vectorización al ofrecer mejoras significativas en la velocidad de recuperación de datos. Este avance es crucial en aplicaciones donde el tiempo de respuesta es crítico, permitiendo procesar y analizar grandes volúmenes de información de manera más eficiente. Sin embargo, una limitación importante de Groq es su compatibilidad selectiva con ciertos modelos de vectorización. Actualmente, solo puede integrarse sin problemas con modelos específicos, lo que implica que los desarrolladores deben adaptar sus proyectos para trabajar con uno de estos modelos compatibles. Entre los modelos de código abierto con los que Groq ha demostrado ser compatible se encuentran Mistral y Llama-3.
Por último, es importante considerar las diversas formas de interactuar con los modelos. A pesar de todas las cualidades que enfatizamos anteriormente sobre Streamlit, presenta algunas desventajas en términos de velocidad de procesamiento, por lo que generalmente se utiliza como una herramienta de demostración. Una de las nuevas opciones que viene a competir es FastHTML, que se integra directamente con frameworks frontend avanzados y ha demostrado ser más rápida que Streamlit. A pesar de su mayor velocidad, FastHTML presenta una curva de aprendizaje más pronunciada y, al ser relativamente nuevo, aún cuenta con menos apoyo de la comunidad.


El panorama está en constante evolución, y lo que hoy es una innovación podría convertirse en el nuevo estándar mañana. Mantenerse al tanto de estos desarrollos y evaluar cuál de estas herramientas puede aportar el mayor valor a tu empresa es crucial. En algunos casos, el modelo RAG Naive puede ser suficiente, pero estar abierto a nuevas opciones puede ofrecer mejoras significativas en eficiencia y funcionalidad. ¿Qué opinas sobre estas ventajas? ¿Crees que los modelos de lenguaje podrían beneficiar a tu organización? Trabajemos juntos.

